

AI 학습용 데이터
AI(인공지능) 학습용 데이터 란?
*인공지능 학습용 데이터는 머신러닝, 딥러닝 등 AI 모델 학습을 위해 활용되는 데이터를 총칭하는 것으로,
원본 데이터와 원본 데이터에 활용 목적에 따라 표시 작업을 한 레이블링(labeling) 데이터를 모두 인공지능 학습용 데이터라 하며,
원본 데이터는 하나지만 레이블링 데이터는 사용 목적에 따라 다양한 형식으로 가공합니다.
(* AI 학습용 데이터에 대한 정의 : NIA IT & Future strategy 2020 총괄본, page. 367)

< AI 학습용 데이터의 구성 >
인공지능 학습용 데이터는 목적에 따라 학습 데이터, 검증 데이터, 평가 데이터로 구분하여 활용합니다. 학습데이터로 AI 모델을 학습시키며(전체 데이터의 50%, 알고리즘이 학습할 데이터로, 모델 학습에 주가 되는 역할), AI 모델 정확도 확인을 위하여 검증데이터를 활용하여 수정하며(데이터의 30%, 학습 중간에 모델의 예측/분류 정확도를 계산하는 역할), 평가 데이터로 성능 평가(데이터의 20%, 모델이 학습 과정에서 경험하지 못했던 데이터로, 학습 후 훈련한 모델의 성능을 평가하는 과정에서 사용)를 진행합니다.
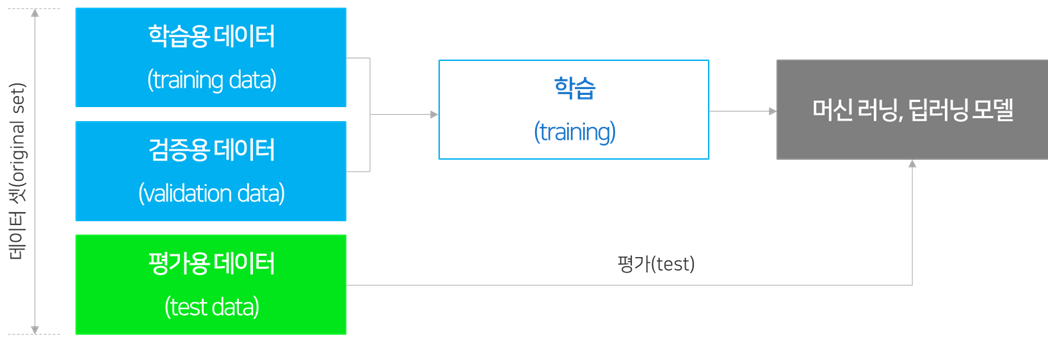
< AI 학습용 데이터의 활용 구분 >
AI 서비스 개발의 주요 과정
AI 서비스를 출시하기 위하여, 여러가지 단계가 필요합니다. 그 중 AI 학습용 데이터 구축은 전체 단계 비용의 80%를 차지할 만큼 매우 중요하고 필수적인 과정입니다. *AI 학습용 데이터 수집 및 AI 서비스 출시까지의 과정은 다음과 같습니다.
(* 출처 : NIA IT & Future strategy 2020 총괄본, page. 368)
1) 수집 : AI 모델 생성을 위한 데이터 수집 또는 제작을 통해 학습용 데이터를 구축하는 과정
2) 가공/레이블링 : 데이터의 종류에 따라 원하는 AI 학습 모델을 제작하기 위해서 편향과 노이즈를 제거하고 속성을 표시하는 작업 과정
3) AI 모델 생성 : 정제된 데이터로 AI를 학습시키고 문제 발생 시 모델을 수정하는 과정을 거쳐 최종 모델을 생성함
4) AI 서비스 출시 : 소비자에게 제공할 수 있는 정도의 서비스 정확도가 나오면 본 서비스를 출시

< AI 학습용 데이터의 가공/레이블링 종류 >
AI 학습용 데이터 구축 방법
자료 : 데이터 수집, AI 모델 개선 관련 약 180개의 논문을 분석·정리하여 도출한 자료
A Survey on Data Collection for ML Yuji Roh 외, IEEE, 2019, 재수정
(데이터 획득) 데이터가 없는 경우 크라우드 소싱이나 데이터 합성을 통해 신규 데이터를 만들고, 기존데이터가있는경우기존데이터를보완, 통합하거나재가공하여데이터획득
(데이터 라벨링) 사람이 데이터를 직접 라벨링하는 방식, 자동화 기술을 통한 대용량의 라벨링방법활용가능
※ 라벨링 방식에 따라 비용과 시간 결과물의 품질 차이 발생 가능
(기존 데이터 활용) 기존 데이터의 편향·노이즈 제거, 재라벨링 등 품질 향상을 통해 기존 데이터를정제하거나, 이미학습된 AI 모델을재학습시키는방식으로 AI 모델개선
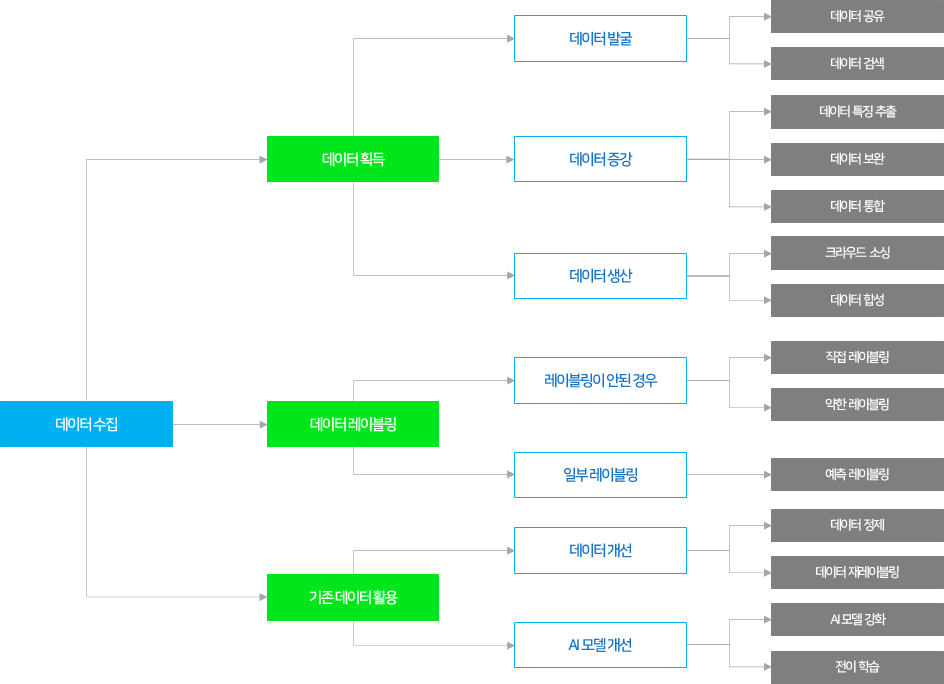
< AI 학습용 데이터의 구축방법 >
데이터 생성 및 라벨링 주요 내용
(출처 : NIA IT & Future strategy 2020 총괄본, page. 370)
| Level 1 | Level 2 | Level 3 | 주요내용 |
|---|---|---|---|
| 데이터 획득 Data acquisition |
데이터 발굴 Discovery |
데이터 공유 sharing |
데이터 세트를 웹에 게시, 클라우드 기반 서비스를 통해 공유해 공동으로 분석·관리·활용 (ex) Google Fusion Tables, CKAN, Quandl, Datamarket, Kaggle |
| 데이터 검색 searching |
다양한 메타 데이터를 사용해 원하는 데이터 세트를 쉽게 검색할 수 있도록 만든 기업 내·외부 시스템 (ex) IBM Data wrangling, Google Data Search(GOODS) - 기업 내부 DB 중심, Google Dataset Search – Web 중심 |
||
| 데이터 증강 Augmentation |
데이터 특징추출 Latent Semantics |
텍스트 데이터에서 데이터의 주요 특징을 분석,잠재 의미를 새롭게 파생하여 학습용 데이터 세트 획득 (ex) Word2vec, GloVe, Doc2Vec, LDA |
|
| 데이터 보완 Entity |
기존 데이터 세트의 누락된 부분에 관련성 높은 데이터를 추가하는 등 기존 데이터 세트를 풍부하게 보완 ex) Octopus, InfoGather |
||
| 데이터 통합 Data Integration |
기존 데이터 세트에 새로 획득한 데이터 세트를 더해 데이터 세트 자체를 확장하는 방법 (ex) Hamlet system, Hamlet++ system |
||
| 데이터 생산 Generation |
크라우드소싱 Crowdsourcing |
사람을 활용하여 전체적인 데이터 세트를 만들기 위해 필요한 작업을 제공(데이터 수집 및 전처리) (ex) Amazon Mechanical Turk, Data Tamer, Corleone |
|
| 데이터 합성 Synthetic data |
자동 기술 등을 활용해 새로운 합성 데이터를 생성하거나 기존 데이터의 누락 부분을 보완 (ex) Generative Adversarial Network(NGAN) |
||
| 데이터 레이블링 Data labeling |
레이블링이 안된 경우 No labeling |
직접 레이블링 Manual labeling |
크라우드 소싱 방식으로 일반 레이블러가 라벨링을 수행, 분야별 데이터 전문가가 검수하는 방식으로 데이터 레이블링 |
| 약한 레이블링 Weak labeling |
정확도보다 양을 우선하는 방식으로 압도적인 대량의 데이터에서 특정 단어를 확인하거나, 데이터에서 특징 정보 추출을 통해 반자동으로 라벨링 (ex) DeepDive, DDLite, Snorkel / KnowltAll, Freebase, Google Knowledge Graph |
||
| 일부 레이블링 some labeling |
예측 레이블링 Semi-supervised learning |
기존 라벨링된 데이터를 활용해 라벨링 되지 않은 데이터를 분류, 회귀, 유사성 예측 등을 수행하여 적절하게 예측하여 라벨링 | |
| 기존 데이터 활용 Existing data |
데이터 개선 Improve data |
데이터 정제 Data cleaning |
기존 라벨링 된 데이터에서 노이즈, 편향을 제거하는 등 데이터 정제를 통해 고품질의 데이터 확보 (ex) HoloClean, ActiveClean, BoostClean, TARS |
| 데이터 재레이블링 Re-labeling |
라벨링 된 데이터를 목적에 따라 다시 라벨링 하거나 라벨링의 품질을 높여 고품질의 데이터 확보 | ||
| AI 모델 개선 Improve model |
AI 모델강화 Make model robust |
기존 AI 모델을 노이즈나 편향에 대해 강하게 만드는 방식으로 AI 모델 성능 개선 (ex) Webly supervised learning : 고품질 데이터, 저품질 데이터 모두에서 AI 모델을 훈련하는 방식 |
|
| 전이 학습 재레이블링 Transfer learning |
훈련 데이터가 충분하지 않은 경우 미리 학습된 모델을 시작 지점으로 활용하여 AI 모델 제작 ex) AlexNet, VGGNet, Google TensorFlow Hub, Google Cloud AutoML |
양질의 AI 학습용 데이터셋 구축은
노하우를 보유한 솔트룩스이노베이션과 함께!
AI 모델 및 서비스는 학습용 데이터셋의 품질에 따라 성능에 지대한 영향을 미칩니다.솔트룩스이노베이션은 언어/음성, 이미지/영상, 의료분야, 자율주행 분야에 특화된 인공지능 학습용 데이터텟 구축 전문 기업으로 정부가 주도하는 데이터댐 및 민간영역의 AI 데이터셋 구축에 대한 노하우를 보유하고 있습니다. 솔트룩스이노베이션과 함께 하면, 멀리 갈 길도 빠르고 정확한 길로 갈 수 있습니다.